CultureLLM
摘要:
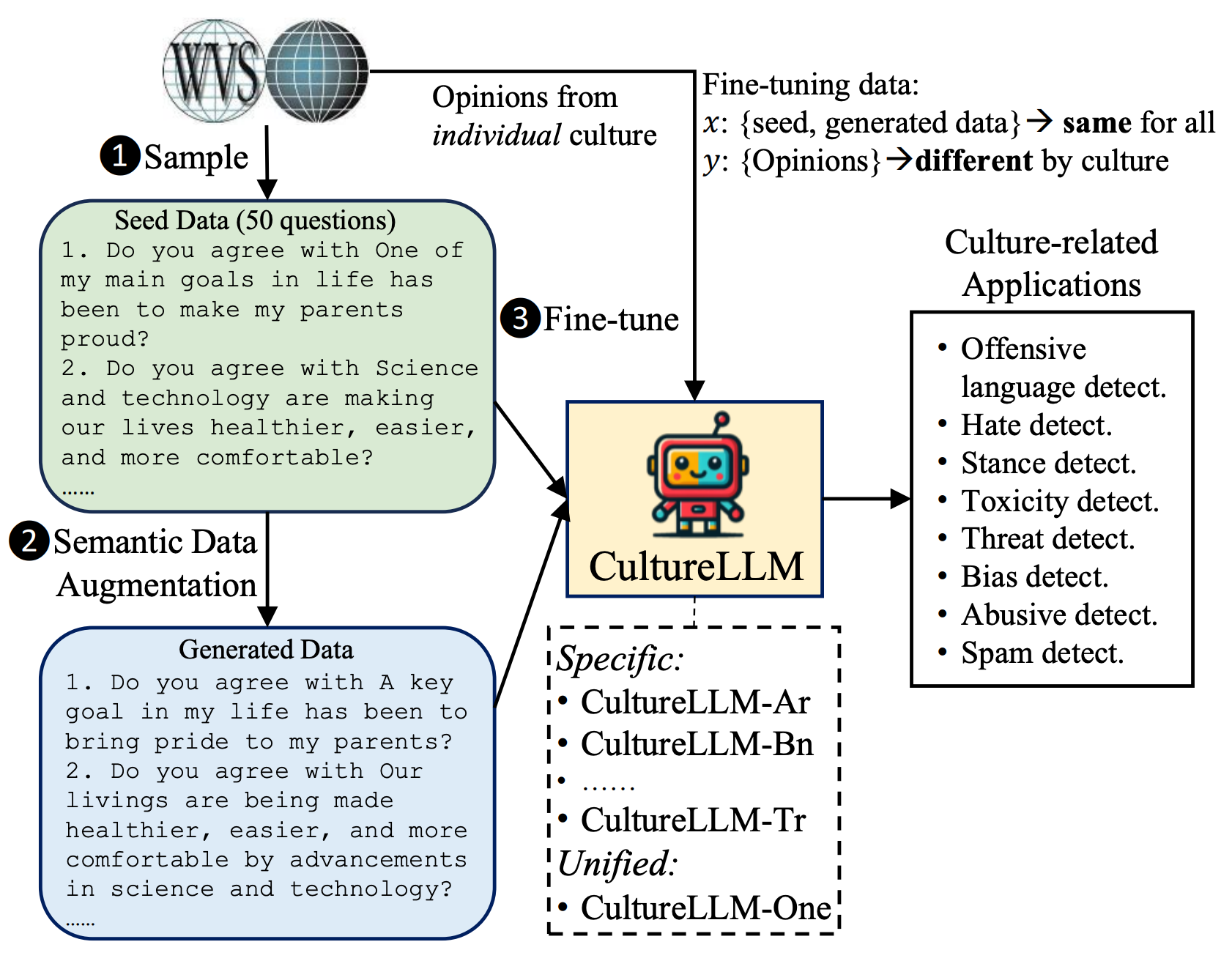
据报道,大型语言模型(LLMs)由于受到英语语料库训练数据的主导,可能偏向于某些文化。由于多语种文化数据通常昂贵难采,现有的处理方法主要通过提示工程或特定文化的预训练来处理。然而,这些方法可能忽视了低资源文化的知识缺陷,并需要大量的计算资源。在本文中,我们提出了CultureLLM,一种将文化差异融入LLMs的成本有效的解决方案。CultureLLM采用世界价值观调查(WVS)作为种子数据,并通过提出的语义数据增强生成语义等价的训练数据。我们仅使用来自WVS的50个种子样本和增强数据,对9种覆盖丰富和低资源语言的文化特定LLMs进行微调,并为这些文化创建一个统一的模型(CultureLLM-One)。在60个与文化相关的数据集上的大量实验表明,CultureLLM在与GPT-4相当或者更好的性能下,明显优于诸如GPT-3.5(提高8.1%)和Gemini Pro(提高9.5%)等各种对手。我们的人类研究表明,生成的样本在语义上等同于原始样本,为LLMs提供了有效的解决方案。
下面是CultureLLM的架构图:
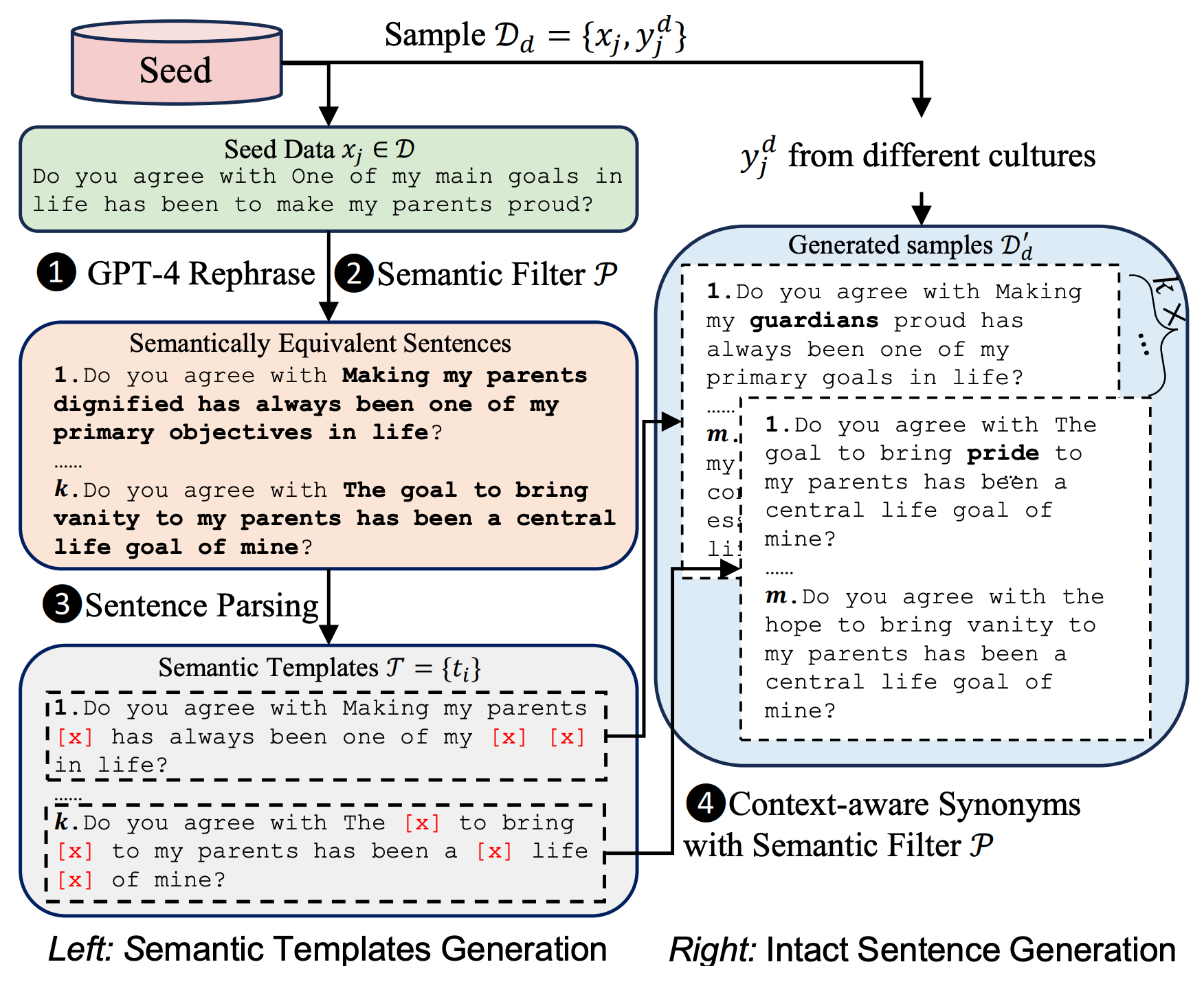
下面是语义数据增强的细节,首先,通过改述、语义过滤和句子解析生成语义模板,然后,通过上下文敏感的同义词替换和语义过滤生成训练样本: